Cómo eludir un baneo de IP al hacer scraping: una guía práctica 2026
Conclusiones Rápidas
Si tu scraper es bloqueado por IP, no cambies los proxies a ciegas. Primero, confirma si el bloqueo es basado en IP, basado en tasa, basado en huella digital, basado en cuenta o específico de un punto final.
Para el scraping, los proxies suelen funcionar mejor que las VPN porque pueden soportar rotación, geo-targeting, control de sesiones y distribución de tráfico a gran escala.
Los proxies residenciales son generalmente la opción más segura para páginas públicas de alto riesgo porque utilizan IPs reales asignadas por ISP. Los proxies ISP estáticos son mejores cuando necesitas una IP estable para sesiones más largas.
Nstproxy es una opción fuerte para este caso de uso porque ofrece proxies residenciales, ISP estáticos, de centro de datos, IPv6, residenciales ilimitados y móviles en una sola plataforma, permitiendo a los scrapers seleccionar el tipo de proxy según el riesgo de bloqueo.
La configuración anti-baneo más confiable combina IPs limpias, un ritmo de solicitudes más lento, encabezados consistentes, rotación consciente de sesiones, almacenamiento en caché y monitoreo de tasas de bloqueo.
Introducción
Un baneo de IP es uno de los problemas más comunes que enfrentan los equipos de scraping web. Un scraper funciona durante las pruebas, recopila unas pocas centenas de páginas, y de repente cada solicitud devuelve 403 Prohibido, 429 Demasiadas Solicitudes, una página CAPTCHA, o una respuesta en blanco. El primer instinto suele ser comprar más proxies o rotar IPs más rápido, pero esa no siempre es la solución adecuada.
Un hilo de Reddit muestra por qué este tema es más complicado que "simplemente usar proxies." Los desarrolladores en la discusión señalaron que simples retrasos entre solicitudes pueden ayudar, mientras que los operadores del sitio dijeron que a menudo bloquean un bloque de red completo cuando el volumen de solicitudes salta repentinamente. Esa es la verdadera lección: los baneos de IP rara vez son causados solo por la dirección IP. Ocurren cuando la IP, la tasa de solicitudes, los encabezados, el comportamiento de la sesión, el punto final objetivo y el patrón de tráfico parecen incorrectos juntos.
Esta guía explica cómo eludir o recuperarse de un baneo de IP al hacer scraping de manera práctica: diagnostica el bloqueo primero, reduce la señal que lo causó y luego utiliza la infraestructura de proxy adecuada para el trabajo.
¿Qué Es un Baneo de IP en el Web Scraping?
Una dirección IP es el identificador de red que un sitio web ve cuando tu scraper envía una solicitud. Le dice al servidor de destino de dónde parece provenir la solicitud. Cuando haces scraping desde tu conexión a casa, servidor en la nube, red de oficina, VPN o proxy, el sitio web puede registrar esa IP y asociarla con el comportamiento de las solicitudes.
Un baneo de IP ocurre cuando un sitio web bloquea solicitudes de una dirección IP específica o un rango de IP. En el scraping, esto generalmente sucede porque el sitio detecta un comportamiento que parece automatizado, excesivo, abusivo o inconsistente con la navegación normal.
Las señales comunes incluyen:
Síntoma
Lo Que Generalmente Significa
403 Prohibido
El sitio rechazó tu solicitud o bloqueó tu IP/sesión.
429 Demasiadas Solicitudes
Excediste los límites de tasa desde una IP o sesión.
Página CAPTCHA
El sitio es sospechoso pero no te ha bloqueado completamente.
Bucle de redirección
El sitio está empujando tu scraper a un flujo anti-bot.
Datos vacíos o falsos
Es posible que el sitio esté degradando las respuestas en lugar de bloquearlas por completo.
Funciona localmente pero falla en el servidor
Tu rango de IP de centro de datos puede estar bloqueado.
Funciona con navegador pero no con script
Los encabezados, cookies, TLS o la huella digital del navegador pueden ser el problema.
El punto importante: un baneo de IP es a menudo el síntoma visible, no la causa raíz.
¿Por Qué los Sitios Web Bloquean IPs de Scraping?
Los sitios web no bloquean IPs aleatoriamente. La mayoría de los bloqueos ocurren porque un scraper crea patrones que son fáciles de distinguir de los usuarios normales.
Un scraper puede enviar demasiadas solicitudes desde una IP en un corto período. Puede acceder a páginas de productos, páginas de búsqueda o APIs en una secuencia predecible. Puede reutilizar los mismos encabezados en miles de solicitudes. Puede acceder a páginas desde una IP de EE. UU. mientras utiliza cookies, configuraciones de idioma o señales de zona horaria de otra región. O puede provenir de un ASN de alojamiento en la nube que el sitio ya considera de alto riesgo.
Esa es la razón por la que cambiar IPs por sí solo a veces funciona por unos minutos y luego falla nuevamente. Si la misma lógica de scraper continúa creando las mismas señales, cada nueva IP eventualmente será quemada.
Cómo los Sitios Web Detectan el Scraping Basado en IP
La mayoría de los sitios modernos utilizan varias capas de detección al mismo tiempo.
1. Volumen de solicitudes. Si una IP envía cientos de solicitudes por minuto, el sitio puede limitar o bloquear rápidamente.
2. Reputación de IP. Las IPs de centros de datos, VPN y proxies abusados son más fáciles de marcar que las IPs limpias residenciales o de ISP.
Prueba Nstproxy gratis ->
3. Patrones de ASN y bloque de red. Incluso si rotas IPs, el objetivo puede notar que todo el tráfico proviene del mismo proveedor de hosting o subred.
4. Desajuste geográfico. Una solicitud de página de producto de EE. UU. desde una IP de EE. UU. parece normal. Una IP de EE. UU. con idioma, zona horaria e historial de cookies no estadounidenses puede parecer menos natural.
5. Inconsistencia de encabezados. La falta de encabezados de navegador, agentes de usuario desactualizados o combinaciones de encabezados imposibles pueden exponer la automatización.
6. Comportamiento de sesión. Rotar IPs con demasiada frecuencia dentro de la misma sesión puede ser tan sospechoso como no rotar en absoluto.
7. Abuso de endpoints. Las páginas de búsqueda, APIs de precios, endpoints de disponibilidad y flujos similares al proceso de compra suelen ser más sensibles que las páginas de contenido estático.
Cómo eludir el baneo de IP al raspar
Para eludir el baneo de IP, prueba los siguientes métodos:
Método 1: Reducir la velocidad de solicitud antes de rotar IPs
La forma más fácil de agotar proxies es enviar demasiadas solicitudes demasiado rápido. Si tu raspador se bloquea después de un número predecible de páginas, tu primera solución debería ser medir la carga.
Un comentarista en Reddit en la discusión mejor posicionada dijo que los retrasos entre solicitudes pueden ayudar porque reducen la carga y hacen que el tráfico parezca menos sospechoso. Ese consejo es básico, pero sigue siendo una de las soluciones más pasadas por alto.
Cómo hacerlo:
Agrega retrasos aleatorios en lugar de pausas fijas.
Usa retroceso exponencial después de respuestas 403, 429, CAPTCHA o de tiempo de espera.
Reduce la concurrencia por dominio, no solo a nivel global.
Evita tormentas de reintento cuando falla una página.
Raspa páginas menos sensibles más rápido y páginas de alto riesgo más lento.
Lógica de ejemplo:
import random
import time
import requests
defpolite_get_with_backoff(url, session, max_retries=5):"""
Realiza una solicitud GET con retroceso exponencial, limitado a 60 segundos.
""" base_delay =5# Retraso inicial en segundos max_delay =60# Tiempo de espera máximofor i inrange(max_retries): response = session.get(url, timeout=20)if response.status_code ==200:return response
if response.status_code in[403,429]:# Calcular retroceso exponencial y limitarlo a max_delay# La función min() asegura que el retraso nunca exceda los 60s delay =min(base_delay *(2** i), max_delay)+ random.uniform(0,1)print(f"Recibido {response.status_code}. Reintentando en {delay:.2f} segundos (Intento {i+1}/{max_retries})...") time.sleep(delay)else:breakreturnNone
Esto no resolverá cada bloqueo, pero evita el patrón más obvio de "una IP golpeando un sitio".
Método 2: No rotar IPs aleatoriamente
La rotación de IP es útil, pero la rotación aleatoria puede romper sesiones y crear nuevas señales de detección. Por ejemplo, si una sesión de cookies salta de Texas a Alemania a India en tres solicitudes, eso no parece un usuario normal.
Un mejor enfoque es rotar por tipo de tarea.
Usa una rotación corta para páginas sin estado como resultados de búsqueda públicos, páginas de listados y páginas de productos sin inicio de sesión. Usa sesiones fijas para flujos que requieren continuidad, como paneles de cuentas, carritos, formularios de varios pasos o páginas donde las cookies importan.
Buenas reglas de rotación:
Tarea de raspado
Rotación recomendada
Listados públicos
Rotar cada pocas solicitudes o cada grupo de páginas.
Páginas de detalles de productos
Rotar por lote o categoría.
Páginas de inicio de sesión/sesiones
Usar sesiones de IP fijas.
Raspado de resultados de búsqueda
Rotar más a menudo y desacelerar.
Endpoints similares a API
Usar retroceso estricto y menor concurrencia.
Monitoreo de larga duración
Usar proxies ISPs estables o sesiones residenciales fijas.
El objetivo no es la rotación máxima. El objetivo es una distribución de tráfico creíble y estable.
Método 3: Usar proxies residenciales de alta calidad para objetivos riesgosos
Cuando un sitio bloquea tráfico de nube, VPN o centros de datos de manera agresiva, los proxies residenciales son generalmente la opción más fuerte. Los proxies residenciales enrutan el tráfico a través de IPs asignadas por ISPs reales, por lo que la solicitud parece más cercana al tráfico normal de consumidores.
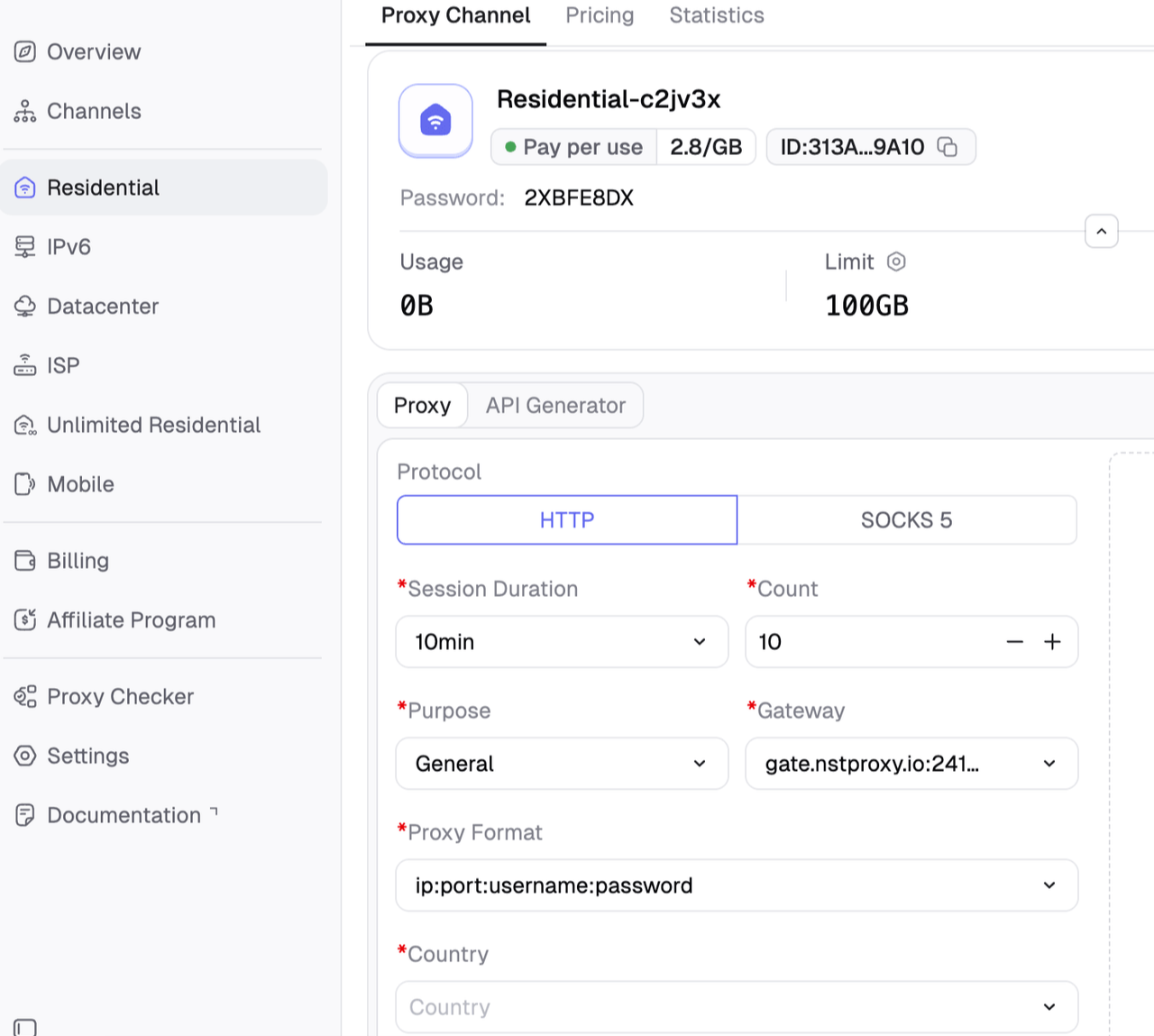
Aquí es donde los proxies residenciales Nstproxy se adaptan naturalmente. Nstproxy proporciona IPs residenciales obtenidas de redes domésticas reales en más de 190 países, con segmentación por país, ciudad y ASN, soporte para HTTPS/SOCKS, reintentos automáticos y rotación de IP. Para equipos de raspado que lidian con baneos de IP, la mayor ventaja no es solo tener más IPs. Es poder elegir IPs que coincidan con el mercado objetivo y rotarlas sin tener que reconstruir constantemente la infraestructura.
Por qué elegir proxies residenciales Nstproxy para el raspado de baneos de IP:
- Reputación real de IP residenciales: mejor adaptada para sitios que desconfían de rangos de centros de datos o VPN. - Gran pool global: útil cuando se raspan páginas de EE. UU., mercados locales, sitios de viajes, SERPs o contenido específico de la región. - Segmentación precisa: filtros de país, ciudad y ASN ayudan a mantener la ubicación de IP alineada con la página objetivo. - Reintentos automáticos y rotación: ayuda a reducir el mantenimiento manual de proxies. - Soporte HTTPS/SOCKS: integración más fácil con pilas de raspado comunes. - Precios flexibles: útil para pruebas antes de aumentar el tráfico.
Cómo usarlo:
Comienza con el país donde se pretende acceder al contenido objetivo.
Utiliza rotación residencial para páginas públicas que no necesitan una sesión de inicio de sesión estable.
Mantén consistentes los encabezados de solicitud, idioma, zona horaria y cookies con la ubicación del proxy.
Rastrear la tasa de bloqueo por pool de IP, endpoint objetivo y volumen de solicitudes.
Escalar solo después de que la tasa de bloqueo se mantenga estable.
Método 4: Utilizar Proxies ISP Estáticos para Sesiones Largas
La rotación residencial no siempre es la respuesta. Algunos flujos de trabajo de raspado necesitan una IP estable. Si el sitio objetivo espera una sesión continua, rotar con demasiada frecuencia puede causar más bloqueos.
Los proxies ISP estáticos son útiles aquí porque combinan confianza similar a la residencial con estabilidad similar a la de centros de datos. Los Proxies ISP Estáticos de Nstproxy están posicionados para tareas de raspado de alto tráfico y sesiones largas, con IPs estáticas de origen ISP y ancho de banda ilimitado.
Quieres mejor confianza que las IPs de centros de datos pero más estabilidad que las IPs residenciales rotativas.
Estás ejecutando trabajos de raspado de bajo volumen pero de larga duración.
Por ejemplo, un scraper de monitoreo de precios puede usar proxies residenciales de Nstproxy para páginas de descubrimiento amplias, luego proxies ISP estáticos para un monitoreo estable de URLs seleccionadas. Esta configuración mixta a menudo rinde mejor que obligar a un solo tipo de proxy a manejar cada tarea.
Método 5: Evitar Pools de Proxies Burned o de Baja Calidad
Los proxies públicos baratos son una de las formas más rápidas de ser baneado. Muchos ya han sido abusados, están en listas negras o compartidos por demasiados usuarios. Incluso si funcionan para algunas solicitudes, a menudo fallan bajo un volumen de raspado real.
Señales de un pool de proxies deficiente:
Señal
Por qué importa
Alta tasa de CAPTCHA en la primera solicitud
La IP puede ya tener mala reputación.
Muchas IPs de un solo ASN
Fácil para los sitios bloquear a nivel de red.
Timeouts frecuentes
Causa picos de reintentos y raspado inestable.
Misma IP reutilizada con demasiada frecuencia
Crea concentración de solicitudes.
Sin control geográfico/sesional
Difícil mantener el tráfico consistente.
Para un raspado serio, la calidad del proxy importa más que la cantidad de proxies. Un pool limpio más pequeño con buenas reglas de rotación puede superar a un enorme pool de baja calidad.
Método 6: Mantener Consistentes Encabezados, Cookies y Ubicación de IP
Many scrapers rotate IPs but forget identity consistency. A request from a US residential IP should not carry headers, cookies, timezone, language, or browsing patterns from another region.
Mantén estas señales alineadas:
Accept-Language
User-Agent
Timezone
Configuraciones de moneda o locales
Cookies
Flujo de referidos
Duración de la sesión
Geolocalización de IP
Si usas un proxy de EE. UU., el perfil de tu navegador o los encabezados de solicitud deberían parecerse a un usuario de EE. UU. Si rotas de un país a otro, comienza una nueva sesión en lugar de reutilizar las mismas cookies.
Método 7: Separar Tráfico de Alto Riesgo y Bajo Riesgo
No cada página merece la misma estrategia de proxy. Una solicitud de la página de inicio, una página de detalles de productos, un endpoint de búsqueda y una API de disponibilidad pueden tener umbrales de bloqueo muy diferentes.
Una configuración práctica es dividir tu scraper en clases de tráfico:
Tipo de tráfico
Nivel de riesgo
Tipo de proxy sugerido
Páginas estáticas
Bajo
Proxies de centros de datos o IPv6
Páginas de productos/categorías
Medio
Proxies residenciales
Páginas de búsqueda
Alto
Proxies residenciales con ritmo más lento
Páginas basadas en sesión
Alto
ISP estáticos o residenciales pegajosos
Flujos solo móviles
Muy alto
Proxies móviles
Rastreo de bajo riesgo a gran escala
Bajo/medio
Proxies de centros de datos, IPv6 o residenciales ilimitados
Nstproxy es útil aquí porque ofrece múltiples productos de proxy en una sola plataforma. Puede usar proxies de centros de datos para rastreos rápidos de bajo riesgo, proxies residenciales para páginas públicas propensas a bloqueos, proxies ISP estáticos para sesiones estables y proxies móviles para entornos de móviles primero.
Método 8: Monitorear la Tasa de Bloqueo Como una Métrica de Producción
Muchos proyectos de scraping fracasan porque los equipos solo notan los bloqueos después de que el trabajo colapsa. Un enfoque mejor es tratar el bloqueo como una métrica operativa.
Rastrear:
Métrica
Por qué importa
Tasa 403
Indicador de bloqueo duro
Tasa 429
Indicador de límite de tasa
Tasa de CAPTCHA
Indicador de sospecha
Páginas por IP exitosa
Salud del grupo de proxies
Reintentos por URL
Estabilidad del scraper
Tasa de tiempo de espera
Calidad de la red o proxy
Tasa de éxito por punto final
Muestra qué páginas son arriesgadas
Tasa de éxito por tipo de proxy
Ayuda a elegir entre residencial, ISP o centro de datos
Si su grupo residencial tiene una tasa de éxito del 95% en páginas de productos pero solo del 50% en páginas de búsqueda, el problema puede ser el comportamiento del punto final en lugar de la calidad del proxy.
Método 9: Usar Caché para Reducir Solicitudes Repetidas
La caché es una de las maneras más subestimadas para evitar bloqueos de IP. Si su scraper solicita repetidamente la misma URL, está creando un riesgo innecesario.
Utilice la caché para:
Páginas de productos que rara vez cambian
Páginas de categorías con paginación estable
Activos HTML estáticos
URLs previamente fallidas
Respuestas de API con intervalos de actualización predecibles
Una regla simple: no vuelva a solicitar la misma URL a menos que los datos probablemente hayan cambiado.
Esto reduce costos, disminuye el uso de proxies y hace que su tráfico sea menos agresivo.
Método 10: Verificar APIs Oficiales y Conjuntos de Datos Públicos
A veces, la mejor manera de eludir un bloqueo de IP es dejar de raspar el punto final bloqueado. Si un sitio ofrece una API oficial, un flujo de datos, un mapa del sitio, un feed RSS, una descarga masiva o un conjunto de datos público, ese camino puede ser más económico y estable que luchar contra los bloqueos.
Esto no significa que las APIs siempre estén disponibles o sean asequibles. Pero verificarlas primero ayuda a evitar construir un scraper frágil cuando existe un camino más limpio.
Proxy vs VPN vs Datos Móviles: ¿Cuál Funciona Mejor?
Opción
Mejor para
Debilidad
VPN
Pruebas manuales, verificaciones rápidas de región
Rotación limitada, a menudo bloqueada, no ideal para escalas
Proxy de centro de datos
Rastreo rápido en sitios de bajo riesgo
Más fácil de detectar en objetivos protegidos
Proxy residencial
Scraping web público con necesidades de mayor confianza
Cuesta más que los proxies de centros de datos
Proxy ISP estático
Sesiones largas, identidad estable, monitoreo
Menos flexible que los grupos residenciales rotativos
Proxy móvil
Plataformas móviles primero o muy sensibles
Costo más alto y no siempre necesario
API de scraping web
Equipos que quieren gestión de desbloqueo
Menos control y puede costar más a gran escala
Para la mayoría de los problemas de bloqueo de IP en scraping, los proxies son mejores que las VPN. Las VPN son útiles para depuración manual, pero el scraping requiere control de rotación, geo-selección, gestión de sesiones y monitoreo a nivel de grupo. Eso es exactamente donde una plataforma de proxy como Nstproxy es más práctica.
Consejo Extra: Confirme Que Realmente Es un Bloqueo de IP
Antes de cambiar de proveedores de proxies o reescribir su scraper, realice un diagnóstico simple. Muchos fracasos de scraping se parecen a bloqueos de IP pero son en realidad límites de tasa, desafíos de JavaScript, problemas de cookies o problemas de huellas dactilares.
Prueba
Cómo verificar
Significado
Mismo URL desde otra red limpia
Abra la URL desde una IP diferente o proxy limpio
Si funciona, es probable que su IP original esté bloqueada.
Misma IP en un navegador normal
Visite manualmente desde la misma IP
Si el navegador funciona pero el script falla, puede haber un problema de huella dactilar o de encabezados.
Tasa de solicitud más baja
Pause de 10 a 30 minutos y reintente lentamente
Si el acceso regresa, el problema puede ser el límite de tasa.
Cambiar de punto final
Intente la página de inicio, página de categoría y punto final de API objetivo
Si solo un punto final falla, el sitio puede bloquear esa vía.
Verificar códigos de respuesta
Registrar 403, 429, redirecciones, CAPTCHA HTML
Diferentes códigos requieren diferentes soluciones.
Un buen scraper debería registrar estas señales automáticamente. Sin registros, está adivinando.
Flujo de Trabajo Anti-Bloqueo Recomendado
Para un proyecto de scraping de producción, utilice este flujo de trabajo:
Clasifique las páginas objetivo. Separe páginas estáticas, listados, páginas de búsqueda y páginas basadas en sesiones.
Registre señales de respuesta. Haga un seguimiento de códigos de estado, páginas de CAPTCHA, redirecciones y respuestas vacías.
Comience despacio. Utilice tasas de solicitud conservadoras antes de aumentar la concurrencia.
Elija el tipo de proxy correcto. Residencial por confianza, ISP por estabilidad, centro de datos por velocidad.
Mantenga las sesiones consistentes. No mezcle una sesión de cookies a través de regiones IP no relacionadas.
Agregue retroceso. Reduzca la velocidad automáticamente después de señales de advertencia.
Cache agresivamente. No vuelva a fetch páginas sin cambios repetidamente.
Revise las métricas de bloqueo semanalmente. Trate el rendimiento del proxy como un sistema medible.
Preguntas Frecuentes
P1. ¿Cómo sé si mi scraper está bloqueado por IP?
Si la misma URL falla desde una IP pero funciona desde otra IP limpia, es posible que estés baneado por IP. Si funciona en un navegador real pero falla en tu scraper, el problema pueden ser los encabezados, las cookies, JavaScript o el fingerprinting en su lugar.
Q2. ¿Pueden los proxies eludir un baneo de IP al raspar?
Sí, los proxies pueden ayudar cuando el bloqueo se basa en la IP. Sin embargo, funcionan mejor cuando se combinan con un ritmo más lento, un manejo de sesiones limpio, encabezados adecuados y reglas de rotación específicas para endpoints.
Q3. ¿Son mejores los proxies residenciales que los proxies de datacenter para raspar?
Los proxies residenciales suelen ser mejores para sitios protegidos o de alto riesgo porque utilizan IPs reales asignadas por el ISP. Los proxies de datacenter son más rápidos y baratos, pero son más fáciles de detectar y bloquear por los sitios web.
Q4. ¿Debería usar un VPN para eludir un bano de IP?
Un VPN puede ayudar con pruebas manuales, pero generalmente no es ideal para raspar. Los proxies son mejores para el raspado a gran escala porque ofrecen rotación, geo-targeting, sesiones persistentes y gestión de pools.
Q5. ¿Por qué sigo siendo baneado después de usar proxies?
Tu scraper puede estar enviando demasiadas solicitudes, rotando IPs incorrectamente, reutilizando cookies inconsistentes, utilizando encabezados sospechosos o golpeando endpoints sensibles de manera demasiado agresiva. La calidad del proxy importa, pero el comportamiento del scraper también es importante.
Q6. ¿Qué producto de Nstproxy debería usar para el raspado de baneos de IP?
Comienza con los Proxies Residenciales de Nstproxy si el objetivo bloquea IPs de datacenter o de VPN. Usa Proxies ISP Estáticos de Nstproxy cuando necesites sesiones largas y estables. Usa proxies de datacenter o IPv6 solo para rastreo de bajo riesgo y alta velocidad.
Resumiendo
Para eludir un baneo de IP al raspar, no te apoyes en un solo truco. Diagnostica el bloqueo, ralentiza los patrones de solicitud, rota IPs inteligentemente, mantén las sesiones consistentes y elige tipos de proxies según el riesgo.
Para la mayoría de los flujos de trabajo de raspado serios, los proxies residenciales de Nstproxy son el mejor punto de partida porque proporcionan IPs residenciales reales, amplia cobertura geográfica, targeting preciso, rotación y altas tasas de éxito. Para sesiones largas, los Proxies ISP Estáticos de Nstproxy son una mejor opción. Utilizados juntos, ofrecen a los equipos de raspado una forma más limpia de recuperarse de baneos de IP y prevenir el siguiente.
Proxifier permite que las aplicaciones de escritorio dirijan el tráfico a través de servidores proxy, incluso cuando esas aplicaciones no admiten configuraciones de proxy directamente. Esta guía explica cómo funciona Proxifier, cómo agregar Nstproxy, cómo crear reglas de proxificación y cómo solucionar problemas de conexión comunes. Está escrita para casos de uso legítimos, como enrutamiento de aplicaciones, resolución de problemas de acceso, pruebas, investigación y flujos de trabajo de proxy controlados.
Lena Zhou
Jul. 1st 2026
Prueba Nstproxy - Empieza tu prueba gratis hoy
110M+ IP reales con 99.9% de acceso exitoso
Acceso inmediato a pools premium de proxies residenciales, datacenter, IPv6 e ISP.
Respuesta media ultrarrapida ~0.5s para tareas de alta concurrencia