周一至周五 09:00 - 18:00(UTC+08:00) 
 ©2026 NST LABS TECH LTD. 保留所有权利。
©2026 NST LABS TECH LTD. 保留所有权利。Lena ZhouGrowth & Integration Specialist
如何在抓取时绕过IP封禁:实用的2026指南
快速总结
-
如果您的爬虫被IP封禁,请不要盲目更换代理。首先确认封禁是基于IP、基于速率、基于指纹、基于账户,还是特定于端点。
-
对于爬取数据,代理通常比VPN效果更好,因为它们可以支持轮换、地理定位、会话控制和大规模流量分配。
-
对于高风险公共页面,住宅代理通常是最安全的选择,因为它们使用真实的ISP分配的IP。当您需要在较长会话中保持稳定的IP时,静态ISP代理更好。
-
Nstproxy非常适合这个用例,因为它在一个平台上提供住宅、静态ISP、数据中心、IPv6、无限住宅和移动代理,让爬虫能够根据封禁风险匹配代理类型。
-
最可靠的反封禁设置结合了干净的IP、较慢的请求间隔、一致的请求头、会话感知轮换、缓存和封禁率监控。
介绍
IP封禁是网络爬虫团队最常遇到的问题之一。爬虫在测试期间正常工作,收集了几百个页面,然后突然每个请求都返回403 Forbidden、429 Too Many Requests、一个CAPTCHA页面,或一个空白响应。第一反应通常是购买更多代理或更快地轮换IP,但这并不总是正确的解决方案。
一个Reddit线程展示了这个话题比“仅仅使用代理”要复杂得多的原因。讨论中的开发者指出,请求之间的简单延迟可以有所帮助,而网站运营者表示当请求量突然激增时,他们通常会封禁整个网段。这是一个真实的教训:IP封禁很少是由IP地址本身造成的。当IP、请求速率、请求头、会话行为、目标端点和流量模式看起来都很异常时,才会发生封禁。
本指南以一种实用的方式解释了如何绕过或恢复IP封禁:首先诊断封禁,减少造成封禁的信号,然后使用适合该工作的代理基础设施。
什么是网络爬虫中的IP封禁?
IP地址是您的爬虫发送请求时,网站看到的网络标识符。它告诉目标服务器请求似乎来自哪里。当您通过家庭连接、云服务器、办公室网络、VPN或代理进行爬取时,网站可以记录该IP并将其与请求行为关联。
IP封禁发生在网站阻止来自特定IP地址或IP范围的请求时。在爬取时,这通常是因为网站检测到了看起来自动化、过度、滥用或与正常浏览行为不一致的行为。
常见迹象包括:
| 症状 | 通常意味着什么 |
|---|
403 Forbidden | 网站拒绝了您的请求或封禁了您的IP/会话。 |
429 Too Many Requests | 您超出了单个IP或会话的速率限制。 |
| CAPTCHA页面 | 网站对您表示怀疑,但并未完全封禁您。 |
| 重定向循环 | 网站将您的爬虫推入反机器人流程。 |
| 空白或虚假数据 | 网站可能在减少响应而不是硬封禁。 |
| 在本地有效但在服务器上失败 | 您的数据中心IP范围可能已被封禁。 |
| 使用浏览器有效但脚本无效 | 请求头、Cookies、TLS或浏览器指纹可能是问题所在。 |
重点是:IP封禁通常是可见的症状,而不是根本原因。
为什么网站会封禁抓取IP?
网站并不是随机封禁IP。大多数封禁发生是因为爬虫创建了易于与正常用户区分的模式。
爬虫可能会在短时间内从一个IP发送过多的请求。它可能以可预测的顺序访问产品页面、搜索页面或API。它可能在成千上万的请求中重用相同的请求头。它可能在使用来自其他地区的Cookies、语言设置或时区信号时,从美国IP访问页面。或者,它可能来自网站已经视为高风险的云托管ASN。
这就是为什么单独更换IP有时能管用几分钟,然后又失败。如果相同的爬虫逻辑继续产生相同的信号,每个新IP最终都会被封禁。
网站如何检测基于IP的爬虫
1. 请求量。 如果一个IP每分钟发送数百个请求,网站可以快速限制或封禁它。
2. IP声誉。 数据中心、VPN和滥用代理IP比干净的住宅或ISP IP更容易被标记。
3. ASN和网段模式。 即使您轮换IP,目标也可能注意到所有流量来自同一托管提供商或子网。
4. 地理位置不匹配。 来自美国IP的美国产品页面请求看起来是正常的。但是,带有非美国语言、时区和Cookie历史记录的美国IP可能看起来不那么自然。
5. 头部不一致。 缺少浏览器头部、过时的用户代理或不可能的头部组合可能会暴露自动化。
6. 会话行为。 在同一会话内过于频繁地轮换IP可能和根本不轮换一样可疑。
7. 端点滥用。 搜索页面、价格API、可用性端点和类似结账的流程通常比静态内容页面更敏感。
如何在抓取时绕过IP禁令
方法1:在轮换IP之前降低请求速度
烧掉代理的最简单方法是发送过多请求过快。如果您的抓取工具在可预测的页面数量后被阻止,则您首先要修复的应是请求节奏。
一位Reddit评论员在排名最高的讨论中表示,请求之间的延迟可以有所帮助,因为它们减少了负载并使流量看起来不那么可疑。这个建议很基本,但仍然是最被忽视的修复之一。
- 添加随机延迟而不是固定的睡眠时间。
- 在收到
403、429、验证码或超时响应后使用指数退避。
- 降低每个域名的并发量,而不仅仅是全球。
- 在页面失败时避免重试风暴。
- 更快地抓取不太敏感的页面,而更慢地抓取高风险页面。
import random
import time
import requests
def polite_get_with_backoff(url, session, max_retries=5):
"""
进行带有指数退避的GET请求,最大限制为60秒。
"""
base_delay = 5 # 初始延迟时间(秒)
max_delay = 60 # 最大等待时间上限
for i in range(max_retries):
response = session.get(url, timeout=20)
if response.status_code == 200:
return response
if response.status_code in [403, 429]:
# 计算指数退避并将其限制在最大延迟时间内
# min()函数确保延迟时间不会超过60秒
delay = min(base_delay * (2 ** i), max_delay) + random.uniform(0, 1)
print(f"收到 {response.status_code}。将在 {delay:.2f} 秒后重试(尝试 {i+1}/{max_retries})...")
time.sleep(delay)
else:
break
return None
这并不能解决所有的封锁,但可以防止最明显的“一个IP猛击一个网站”模式。
方法2:不要随机轮换IP
IP轮换是有用的,但随机轮换可能会破坏会话并产生新的检测信号。例如,如果一个Cookie会话在三次请求中从德克萨斯州跳到了德国再到印度,这看起来就不像正常用户的行为。
对无状态页面(如公共搜索结果、列表页面和非登录产品页面)使用短轮换。对需要连续性的工作流(如账户仪表板、购物车、多步骤表单或Cookie重要的页面)使用粘性会话。
| 抓取任务 | 推荐轮换 |
|---|
| 公共列表 | 每几次请求或每组页面轮换。 |
| 产品详细页面 | 按批次或类别轮换。 |
| 登录/会话页面 | 使用粘性IP会话。 |
| 搜索结果抓取 | 更频繁地轮换并减慢速度。 |
| API类端点 | 使用严格的退避并降低并发量。 |
| 长期监控 | 使用稳定的ISP代理或粘性住宅会话。 |
方法3:对高风险目标使用高质量的住宅代理
当一个网站积极封锁云、VPN或数据中心流量时,住宅代理通常是最强的选择。住宅代理通过真实ISP分配的IP引导流量,因此请求看起来更接近正常的消费者流量。
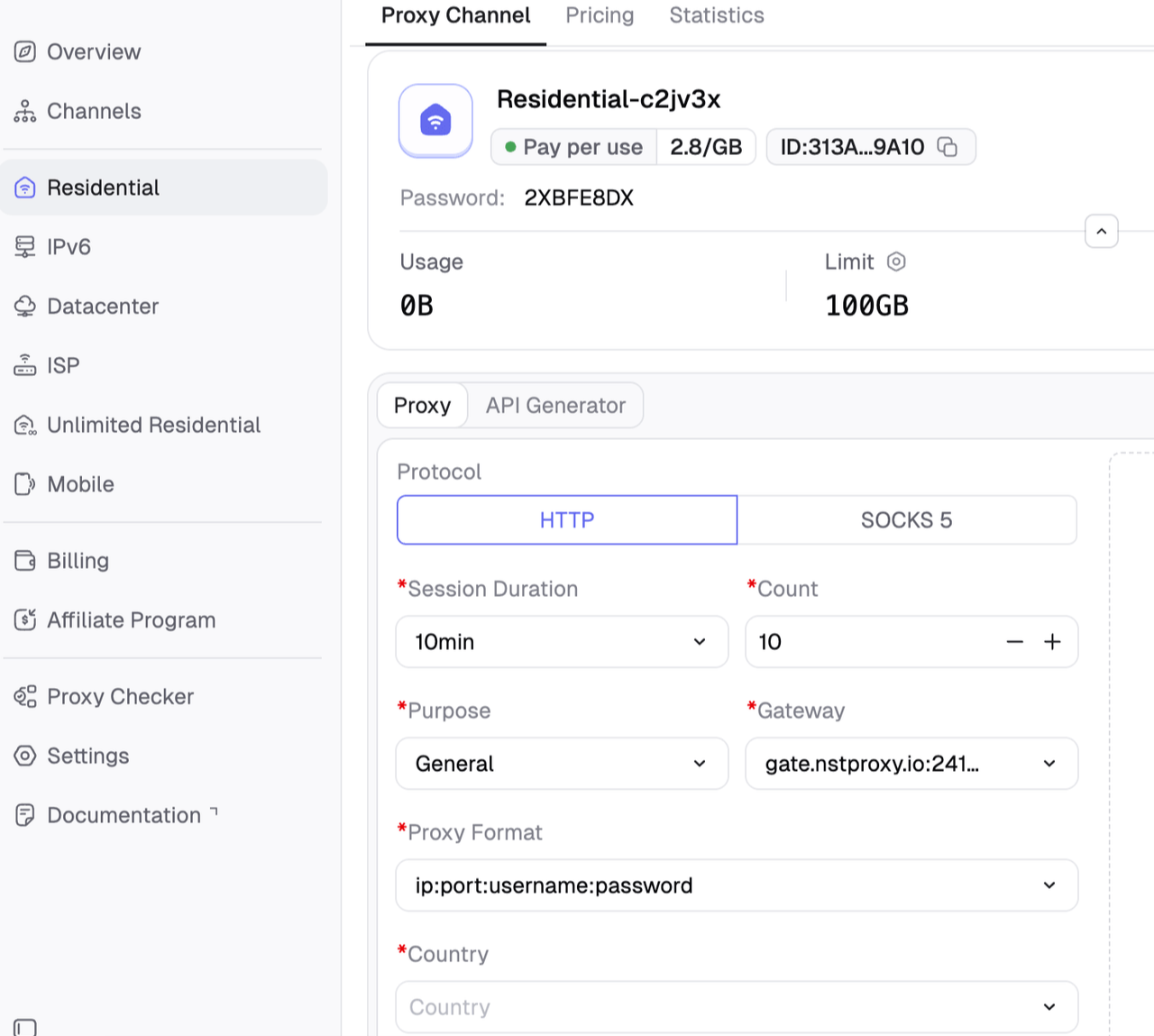
这就是Nstproxy住宅代理自然而然相符的地方。Nstproxy提供来自190多个国家的真实家庭网络的住宅IP,支持国家、城市和ASN定位、HTTPS/SOCKS、自动重试和IP轮换。对于处理IP禁令的抓取团队来说,最大优势不仅在于拥有更多的IP,而在于能够选择与目标市场匹配的IP并在不需要不断重建基础设施的情况下轮换它们。
为什么选择Nstproxy住宅代理进行IP禁令抓取:
- 真实住宅IP声誉:更适合不信任数据中心或VPN范围的网站。
- 大型全球池:在抓取美国页面、本地市场、旅游网站、搜索引擎结果页面或特定地区内容时很有用。
- 精确定位:国家、城市和ASN过滤器有助于保持IP位置与目标页面一致。
- 自动重试和轮换:有助于减少手动代理维护。
- 支持HTTPS/SOCKS:更容易与常见的抓取技术栈集成。
- 灵活定价:在扩大流量之前进行测试时很有用。
如何使用:
-
从目标内容要访问的国家开始。
-
对于不需要稳定登录会话的公共页面,使用住宅轮换。
-
保持请求头、语言、时区和cookie与代理位置一致。
-
按IP池、目标端点和请求量跟踪阻塞率。
-
仅在阻塞率保持稳定后再进行扩展。
方法4:使用静态ISP代理进行长会话
住宅轮换并不总是答案。某些抓取工作流程需要稳定的IP。如果目标网站期望持续会话,频繁轮换可能会导致更多的阻塞。
静态ISP代理 在这里很有用,因为它们将住宅般的信任与数据中心般的稳定性结合在一起。Nstproxy静态ISP代理适用于高流量和长会话的抓取任务,提供ISP源的静态IP和无限带宽。
- 您需要相同的IP进行完整会话。
- 目标阻止频繁的IP更改。
- 您在持续监控页面。
- 您希望比数据中心IP更具信任,但比轮换住宅IP更稳定。
- 您进行的是低流量但长时间的抓取作业。
例如,价格监控抓取器可以使用Nstproxy住宅代理进行广泛发现页面的抓取,然后使用静态ISP代理稳定监控选定的URL。这种混合设置通常比强制一种代理类型处理每个任务效果更佳。
方法5:避免被封或者低质量的代理池
廉价的公共代理是被封禁的最快方式之一。许多代理已经被滥用、列入黑名单或被过多用户共享。即使它们在少数请求中有效,它们在实际抓取量下通常会失败。
| 信号 | 为什么重要 |
|---|
| 首次请求的CAPTCHA率高 | 该IP可能已有不良声誉。 |
| 来自一个ASN的多个IP | 很容易在网络层面被网站阻止。 |
| 经常超时 | 导致重试峰值和不稳定的抓取。 |
| 同一IP重复使用过于频繁 | 导致请求集中。 |
| 没有地理/会话控制 | 难以保持流量一致。 |
对于严肃的抓取,代理质量比代理数量更重要。拥有良好轮换规则的小型干净池可以超越一个巨大的低质量池。
方法6:保持请求头、cookie和IP位置一致
许多抓取者轮换IP但忘记身份的一致性。来自美国住宅IP的请求不应携带来自其他地区的请求头、cookie、时区、语言或浏览模式。
- Accept-Language
- User-Agent
- 时区
- 货币或区域设置
- Cookies
- 引用流量
- 会话持续时间
- IP地理位置
如果您使用美国代理,您的浏览器配置文件或请求头应类似于美国用户。如果您从一个国家轮换到另一个国家,请开始一个新会话而不是重复使用相同的cookie。
方法7:将高风险和低风险流量分开
并非每个页面都值得相同的代理策略。主页请求、产品详细页面、搜索端点和可用性API可能有非常不同的阻塞阈值。
| 流量类型 | 风险级别 | 建议的代理类型 |
|---|
| 静态页面 | 低 | 数据中心或IPv6代理 |
| 产品/类别页面 | 中 | 住宅代理 |
| 搜索页面 | 高 | 住宅代理,速度较慢 |
| 基于会话的页面 | 高 | 静态ISP或粘性住宅代理 |
| 移动专用流量 | 非常高 | 移动代理 |
| 大规模低风险爬虫 | 低/中 | 数据中心、IPv6或无限住宅代理 |
| Nstproxy在这里非常有用,因为它在一个平台上提供了多种代理产品。您可以使用数据中心代理进行快速低风险爬取,使用住宅代理针对容易被封的公共页面,使用静态ISP代理以保持稳定的会话,以及使用移动代理以适应移动优先的环境。 | | |
方法8:将封禁率视为生产指标进行监控
许多爬取项目失败是因为团队只在工作崩溃后注意到封禁。一个更好的方法是将封禁视为一个运营指标。
| 指标 | 重要性 |
|---|
| 403率 | 硬封禁指标 |
| 429率 | 限流指标 |
| CAPTCHA率 | 怀疑指标 |
| 每个成功IP的页面数 | 代理池健康 |
| 每个URL的重试次数 | 爬虫稳定性 |
| 超时率 | 网络或代理质量 |
| 按端点的成功率 | 显示哪些页面存在风险 |
| 按代理类型的成功率 | 帮助选择住宅、ISP或数据中心代理 |
如果您的住宅池在产品页面上的成功率为95%,而搜索页面只有50%,问题可能是端点行为而非代理质量。
方法9:使用缓存减少重复请求
缓存是避免IP封禁的最被低估的方法之一。如果您的爬虫重复请求相同的URL,您正在创造不必要的风险。
- 很少变动的产品页面
- 稳定的目录页面
- 静态HTML资源
- 先前失败的URL
- 具有可预测更新间隔的API响应
一个简单的规则:除非数据有可能已更改,否则不要再次请求相同的URL。
这可以减少成本,降低代理使用率,并使您的流量不那么激进。
方法10:检查官方API和公共数据集
有时,绕过IP封禁的最佳方法是停止爬取被封的端点。如果一个网站提供官方API、数据源、站点地图、RSS源、大宗下载或公共数据集,那么这条路径可能比与封禁作斗争更便宜和更稳定。
这并不意味着API总是可用或经济。但首先检查它们可以帮助您避免在存在更清晰路径时构建脆弱的爬虫。
代理与VPN与移动数据:哪个效果最佳?
| 选项 | 最适合 | 弱点 |
|---|
| VPN | 手动测试,快速区域检查 | 旋转有限,常被封禁,不适合大规模使用 |
| 数据中心代理 | 在低风险网站上的快速爬取 | 在受保护的目标上更容易被检测到 |
| 住宅代理 | 公共网页爬取,信任需求更高 | 比数据中心代理成本更高 |
| 静态ISP代理 | 长时间会话,稳定身份,监控 | 比旋转住宅池灵活性差 |
| 移动代理 | 移动优先或非常敏感的平台 | 成本更高且并非总是必要 |
| 网络爬虫API | 想要管理解封的团队 | 控制较少,可能大规模成本更高 |
对于大多数爬虫IP封禁问题,代理比VPN更有效。VPN对于手动调试很有用,但爬取需要旋转控制、地理定位、会话管理和池级监控。这正是像Nstproxy这样的代理平台更具实用性的地方。
附加提示:确认这真的是IP封禁
在更换代理提供商或重写爬虫之前,进行简单诊断。许多爬虫失败看起来像是IP封禁,但实际上是限流、JavaScript挑战、Cookie问题或指纹问题。
| 测试 | 如何检查 | 意义 |
|---|
| 从另一个干净网络请求相同的URL | 从不同的IP或干净代理打开该URL | 如果可以访问,您的原始IP很可能被封禁。 |
| 在正常浏览器中使用相同的IP | 从相同的IP手动访问 | 如果浏览器可以工作但脚本失败,问题可能是指纹或头部信息。 |
| 降低请求率 | 暂停10-30分钟并慢慢重试 | 如果重新获得访问,问题可能是限流。 |
| 更改端点 | 尝试主页、分类页面和目标API端点 | 如果只有一个端点失败,网站可能会封锁该路径。 |
| 检查响应代码 | 记录403、429、重定向、CAPTCHA HTML | 不同的代码需要不同的修复。 |
好的爬虫应自动记录这些信号。没有日志,您就是在猜测。
推荐的反封禁工作流程
- 分类目标页面。将静态页面、列表、搜索页面和基于会话的页面分开。
- 记录响应信号。跟踪状态代码、CAPTCHA页面、重定向和空响应。
- 先慢后快。在增加并发之前使用保守的请求速率。
- 选择正确的代理类型。住宅代理用于信任,ISP用于稳定,数据中心用于速度。
- 保持会话一致性。不要在无关的IP区域混合使用一个Cookie会话。
- 添加回调。警告信号后自动减速。
- 积极缓存。不要重复获取未更改的页面。
- 每周审查封禁指标。将代理性能视为可测量的系统。
常见问题
Q1. 我如何知道我的爬虫是否被IP封禁?
如果同一个URL在一个IP地址上无法访问,但在另一个干净的IP地址上可以访问,那么你可能被IP禁止。如果在真实浏览器中可以正常工作,但在你的爬虫中失败,那么问题可能出在头部、cookies、JavaScript或指纹识别上。
Q2. 代理可以绕过IP禁止吗?
是的,当阻止是基于IP时,代理可以提供帮助。然而,最好将它们与较慢的请求速率、干净的会话处理、适当的头部和特定于端点的轮换规则结合使用。
Q3. 住宅代理比数据中心代理更适合抓取吗?
住宅代理通常更适合受保护或高风险的网站,因为它们使用真实的ISP分配的IP。数据中心代理更快且更便宜,但它们更容易被网站检测和屏蔽。
Q4. 我应该使用VPN来绕过IP禁令吗?
VPN可以帮助进行手动测试,但通常不适合抓取。代理更适合可扩展的抓取,因为它们提供轮换、地理定位、持久会话和池管理。
Q5. 为什么我在使用代理后仍然被禁止?
你的爬虫可能发送了过多的请求、错误地轮换IP、重复使用不一致的cookies、使用可疑的头部,或太激烈地请求敏感端点。代理的质量很重要,但爬虫的行为也很重要。
Q6. 我应该使用哪个Nstproxy产品来抓取IP禁令?
如果目标阻止数据中心或VPN IP,请从Nstproxy住宅代理开始。当你需要稳定的长会话时,请使用Nstproxy静态ISP代理。仅在低风险、高速抓取时使用数据中心或IPv6代理。
总结
要在抓取时绕过IP禁令,不要依赖单一技巧。诊断阻止、减慢请求模式、智能轮换IP、保持会话一致,并根据风险选择代理类型。
对于大多数严肃的抓取工作流,Nstproxy住宅代理是最好的起点,因为它们提供真实的住宅IP、广泛的地理覆盖、精确的定位、轮换和强大的成功率。对于长会话,Nstproxy静态ISP代理更合适。将它们结合使用,可以为抓取团队提供更干净的方式来从IP禁令中恢复并防止下一个禁令。
立即访问住宅、数据中心、IPv6 与 ISP 高质量代理池。